Abstract
Computational pathology can lead to saving human lives, but models are annotation hungry and pathology images are notoriously expensive to annotate. Self-supervised learning has shown to be an effective method for utilizing unlabeled data, and its application to pathology could greatly benefit its downstream tasks. Yet, there are no principled studies that compare SSL methods and discuss how to adapt them for pathology. To address this need, we execute the largest-scale study of SSL pre-training on pathology image data, to date. Our study is conducted using 4 representative SSL methods on diverse downstream tasks. We establish that large-scale domain-aligned pre-training in pathology consistently out-performs ImageNet pre-training in standard SSL settings such as linear and fine-tuning evaluations, as well as in low-label regimes. Moreover, we propose a set of domain-specific techniques that we experimentally show leads to a performance boost. Lastly, for the first time, we apply SSL to the challenging task of nuclei instance segmentation and show large and consistent performance improvements under diverse settings.
Links

Pre-training datasets
We collect 20,994 Whole Slide Images (WSIs) from The Cancer Genome Atlas (TCGA) and 15,672 WSIs from TULIP that is an internally collected dataset. Both datasets consist of Hematoxylin & Eosin (H&E) stained WSIs of various cancers. For pre-training data, we extract at most 1,000 patches of resolution 512 x 512 pixels from each slide, resulting in a total of 32.6M patches (19M from TCGA and 13.6M from TULIP). The pre-training data covers 20x (0.5µm/px) and 40x (0.25µm/px) objective magnification. Unless specified otherwise in the paper, the experiment was done by the TCGA dataset only.
Self-supervised Pre-training for Pathology
The performance of SSL methods can vary greatly depending on the composition of training data and the selected set of data augmentation methods. Therefore, we attempt to understand the characterstic of pathology data compared to natural images and come up with techniques to adapt current SSL methods for pathology images. Compared to natural images,
- No canonical orientation: image remains plausible even if the images are oriented.
- Lower color variation: natural images tend to have large range of colors due to the diversity of represented objects, while pathology images tend to display similar color distributions (e.g., purple and pink staining).
- Different FoVs: objects of interest can vary depending on FoV.
Based on the analysis, we design a set of augmentation by considering the above characteristics. They are able to be easily adopted in the pre-training stage. We demonstrate the benefit of these techniques on various downstream tasks.

In the pathology domain, we explore the 4 major paradigms of SSL as commonly discussed in the literature. Among paradigms, we select the one representative method and perform large-scale pre-training.
- Contrastive Learning: MoCo V2
- Non-Contrastive Learning: Barlow Twins
- Clustering: SwAV
- SSL with VisionTransformer: DINO
We use the ResNet-50 architecture for MoCo V2, Barlow Twins, and SwAV. For DINO, we use ViT-small with different patch sizes, 16x16 and 8x8. All pre-training was performed on 64 NVIDIA V100 GPUs. For ease of analysis, we adopt the concept of the ImageNet epoch. The model is trained for 200 ImageNet epochs across all pre-trainings.
Experiments
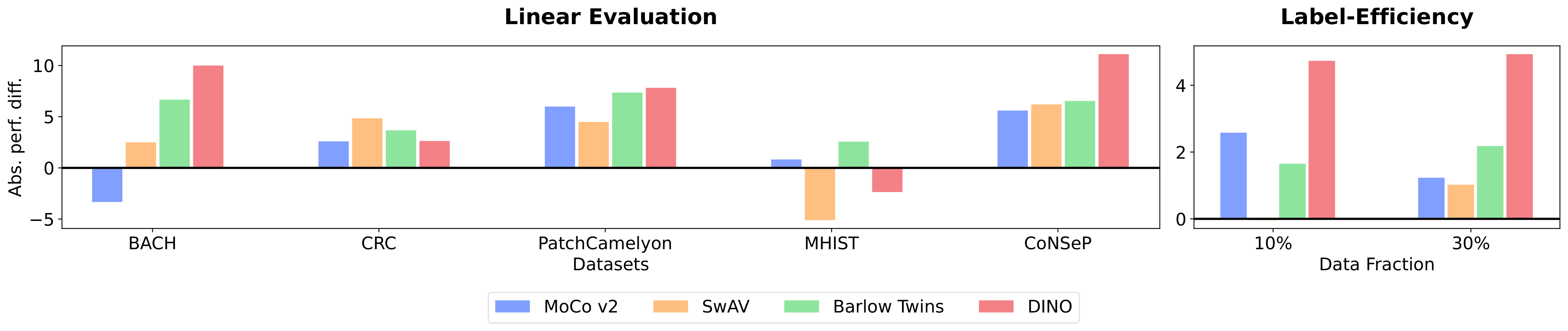
We carry out various experiments on the downstream tasks of image classification and nuclei instance segmentation tasks. For image classification, the following four datasets are used for our evaluation: BACH (four-class breast cancer type classification), CRC (nine-class human colorectal cancer type classification), MHIST (binary class colorectal polyp type classification), and PCam (binary class breast cancer type classification). For nuclei instance segmentation, we use CoNSeP which contains segmentation masks for each cell nucleus along with nuclei types.
Discussion
Through our experimental findings, we attempt to address a few questions that can naturally arise in the minds of practitioners seeking to leverage large-scale pre-training for the purpose of achieving domain-aligned pre-training advantages in pathology downstream tasks.
Should we pre-train on pathology data?
Yes – We have consistently demonstrated that pre-training on pathology data out-performs supervised pre-training on ImageNet by performing comprehensive experiments on many SSL methods and datasets. Our experiments demystify and confirm the effectiveness of domain-aligned SSL pre-training on the pathology domain.
Which SSL method is best?
We find that there is no clear winner. In our study, we evaluate on two important downstream tasks in the pathology domain – image classification and nuclei instance segmentation – and perform various experiments to compare both the representation quality and transferability of pre-trained weights. All SSL methods applied with domain-aligned pre-training generally perform well, and only minor tendencies can be observed such as the fact that Barlow Twins performs well in linear evaluations and MoCo v2 performs well during fine-tuning evaluations. Thus, instead of focusing on selecting a specific SSL method, we recommend that practitioners focus on curating large-scale domain-aligned datasets for SSL pre-training.
What is a key ingredient for successful self-supervised pre-training?
Domain knowledge – our proposed set of techniques are fully based on observations in pathology, and are experimentally shown to be effective. By incorporating domain-specific knowledge into the pre-training step, e.g., using stain augmentation and extracting patches from multiple FoVs, we go beyond the performance one can get from naively applying SSL to a new dataset.
Citation
@inproceedings{kang2022benchmarking,
author={Kang, Mingu and Song, Heon and Park, Seonwook and Yoo, Donggeun and Pereira, Sérgio},
title={Benchmarking Self-Supervised Learning on Diverse Pathology Datasets},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month={June},
year={2023},
pages={TBU}
}
License
Pre-trained weights are bound by Public License issued from Lunit Inc. Note that, the weights must be used non-commercially, meaning that the weights must be used for research-only purpose.
Acknowledgments
We thank to Mohammad Mostafavi and Biagio Brattoli for reviewing early draft and useful comments. Also, we specially thank to HyunJae Lee and Gihyeon Lee for providing the infrastructure enabling us to perform large-scale pre-training.